|
 Accueil Accueil |
|
|
|
|
|
|
|
Formations |
|
|
|
|
|
|
|  |
Big Data Hortonworks
Plateforme Hortonworks
Nouvelle page 3
Notre société MANAGEMENT INFORMATIQUE réalise aussi des missions d'architecture technique de systèmes Big Data.
Nos prestations consistent à apporter notre expertise sur les distributions Hadoop : Hortonworks, Cloudera HDP, MAPR, définition des besoins, matrice de critères, choix de logiciels répondant aux besoins, rédaction de dossiers d'architecture technique, tests sur machine virtuelle, validation des solutions préconisées.
A la demande du client la prestation est adaptée selon les besoins du client, son architecture spécifique, son environnement réseau, machines / serveurs, logiciels déjà existants.
Â
Rappel historique :Â
le 21 Juin 2017, IBM met un terme à sa distribution Hadoop, BigInsights 4.  Hortonworks vend la suite dâoutils analytiques Data Science Experience dâIBM mais aussi BigSQL le moteur de requête SQL-on-Hadoop.
le 21 Mars 2019, une nouvelle plateforme était annoncée CDP : Cloudera Data Platform résultat de la fusion entre Cloudera et Hortonworks.Â
Cette plateforme intègre le meilleur des fonctionnalités clé de HDP : Horton Data Platform et de CDH : Cloudera Data Hub. La v1 de CDP est disponible en Juin 2019 sur les Clouds publics dâAWS et de Microsoft Azure.
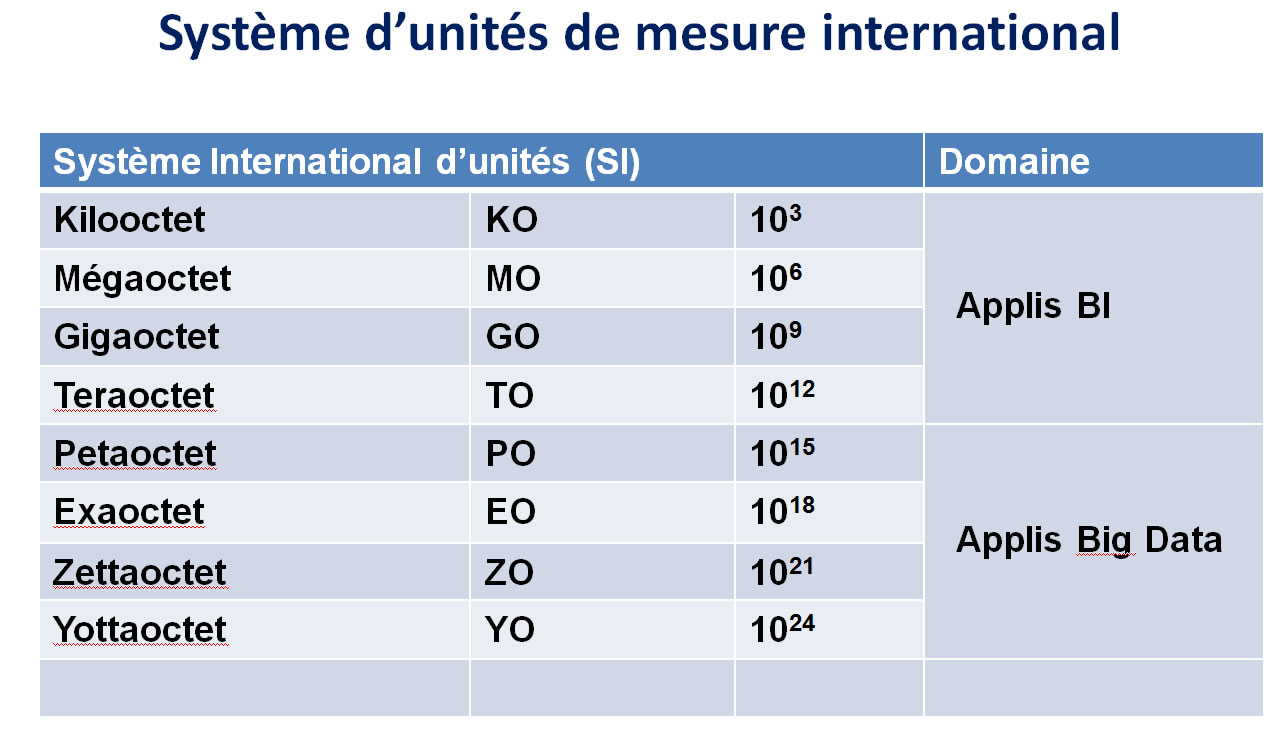
Règle des 3VÂ
constitue un élément essentiel du Big Data :
. La volumétrie très importante des données,
. La variété des sources de données
. La vélocité des traitements de collecte, de stockage et de partage des données.
Ces 3 élements constituent une composante fondamentale du Big Data.
Les Besoins des clients :
- Quantité de données importantes contenant potentiellement de la valeur ajoutée, en sommeil ou qui n'est plus utilisée à cause de considérations de taille et de performances
- Volumes importants de données non structurées ou semi-structurées qui ne s'intègrent pas facilement : Tweets, logs...
- Pas évident de savoir ce qui doit être analysé.
- L'information est distribuée sur plusieurs serveurs et/ou internet.
- Certaines infos ont une durée de vie courte.
- Les volumes peuvent devenir extrèmement importants.
- Une analyse est nécessaire dans le contexte des infos existantes.
|
Â
 Â Â
|
Avantages du Big Data et de lâanalyse de données :
- Pouvoir traiter et stocker rapidement des volumétries de données très grandes, des données de nature différente Images, vidéos, textuelles, vocales, structurées, non structurées, capteurs, IoT, infos temps réel, logs
- Bien adapté à l'IA et au Machine Learning, les plateformes Big Data permettent d'explorer un nombre de combinaisons très important et donc d'obtenir des prédictions plus fiables. Lâexhaustivité des réponses augmente la confiance dans les données. Cela permet dâadopter une méthode de résolution des problèmes radicalement différente.
- L'extensibilité des systèmes de stockage : conteneurs, virtualisation permet d'adapter rapidement les SI à l'augmentation des volumétries notamment en Cloud.
- De nouveaux modes de communication sont apparus au 21ième siècle sont apparus : réseaux sociaux notamment. Le Big Data permet le stockage de données perso de millions d'individus, réparties virtuellement en différents datacenters.
Inconvénients du Big Data :
- Demande l'installation d'infrastructures importantes pour stocker ces volumétries importantes.
- Parfois le Cloud peut être une solution avantageuse pour faire des POC ou des tests de logiciels Hadoop.
- La prolifération des Datacenters dans le monde ( même sous-marins ) consomme une énergie importante, qui est quantifiable aujourd'hui.
 |
 |
Â
Â
Résumé des logiciels Big Data distribution Hortonworks:
Logo |
Logiciel |
Description |
|
Â

|
Console dâadministration Ambari
(*) Ambari is a locality in Guwahati, India |
Ambari est la console dâadministration de la plateforme Hadoop Hortonworks
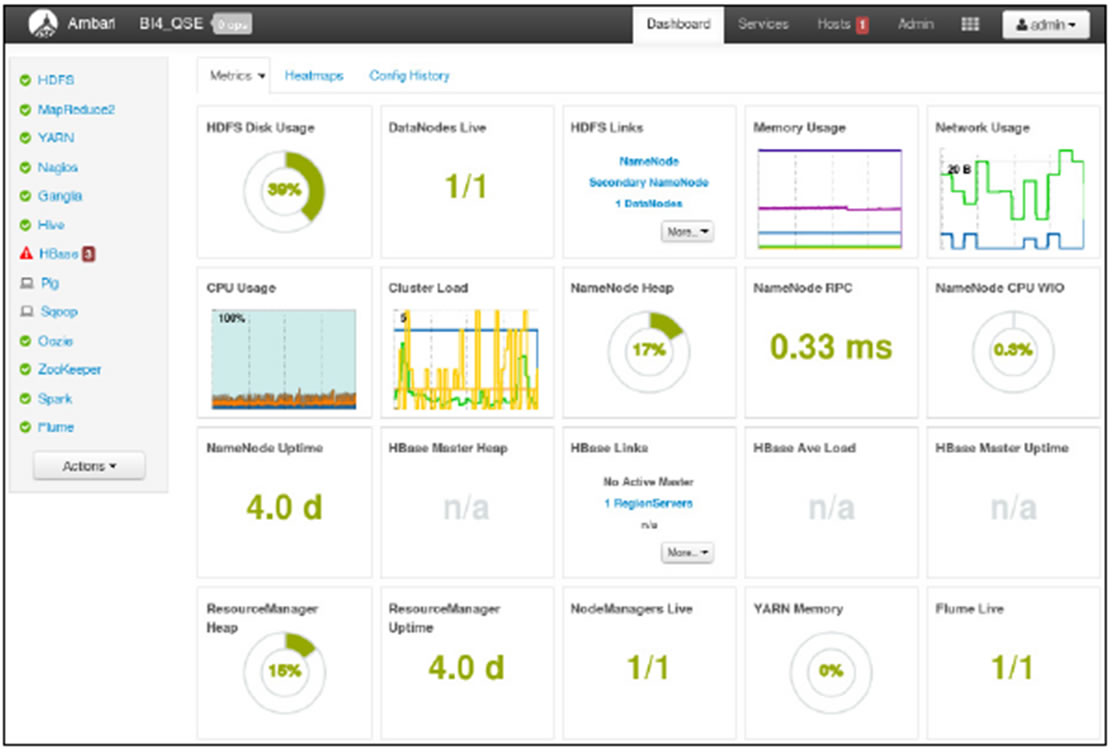
Ambari ne se limite pas à Hadoop mais permet de gérer également les outils de lâécosystème.
Les outils annoncés sont :
- Â HDFS
- Â Hadoop 1.0 uniquement, la version 2.0 devrait
-    être supportée courant Juin
- Â MapReduce
- Â Hive, HCatalog
- Â Oozie
- Â HBase
- Â Ganglia, Nagios
- Tous les outils de la distribution dâHortonWorks
Ambari comprend 2 composants :
un serveur
des agents installés sur chaque machine du cluster
Ambari fournit un dashboard dont le rôle est de fournir un résumé :
-   de lâétat des services
 des informations issues de Ganglia et de Nagios
 de lâexécution des jobs  |
 |
Ganglia 3.7.2
(*) Ganglia tire son origine en anatomie de ganglion |
Ganglia est un moniteur de système distribué extensible utilisé par des composants à hautes performances tels que des clusters ou des grids.
Son but est de permettre à l'utilisateur de visualiser des statistiques à distance ( temps réel ou historisées ) telles que des moyennes de temps de chargement CPU ou sur l'utilisation du réseau ) pour toutes les machines qui doivent être suivis. |
 |
Nagios 4.4.4
(*) Nagios tire son origine de NetSaint |
Nagios est un logiciel Open Source permettant le monitoring du système, du réseau et de l'infrastructure.
Nagios offre le monitoring et les services d'alerte pour les serveurs, les switches, les applications, et les services. Il alerte les utilisateurs quand quelque chose se passe mal et les alerte une 2ième fois quand l'incident a été résolu. |
 |
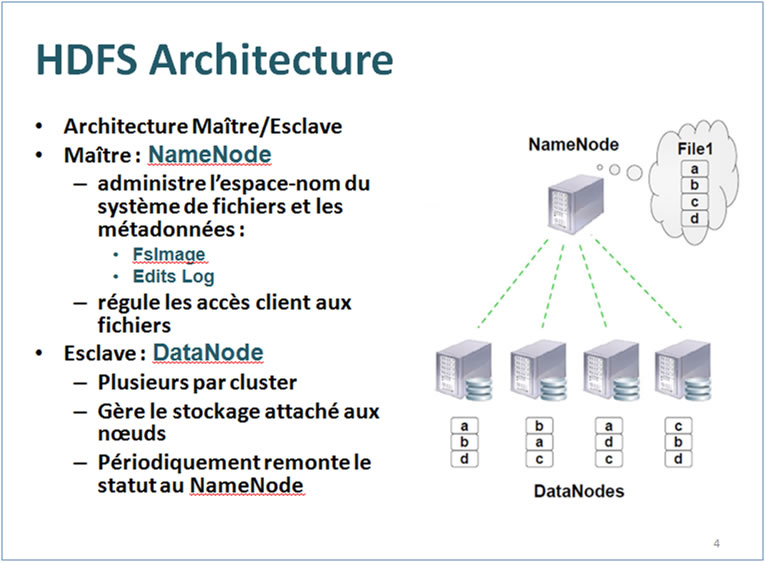
HDFS |
Hadoop Distributed File System : Système de gestion de Fichiers de Hadoop
HDFS est le système de fichier distribué de Hadoop Apache. Il sâagit dâun composant central du Framework de Apache, et plus précisément de son système de stockage.Â
Architecture Maître / esclave : chaque cluster comprend un NameNode ( serveur principal )  Chaque nÅud comprend aussi un ou plusieurs DataNodes sur lesquels sont stockés les données.
Architecture de HDFS :
Démarrage NameNode :
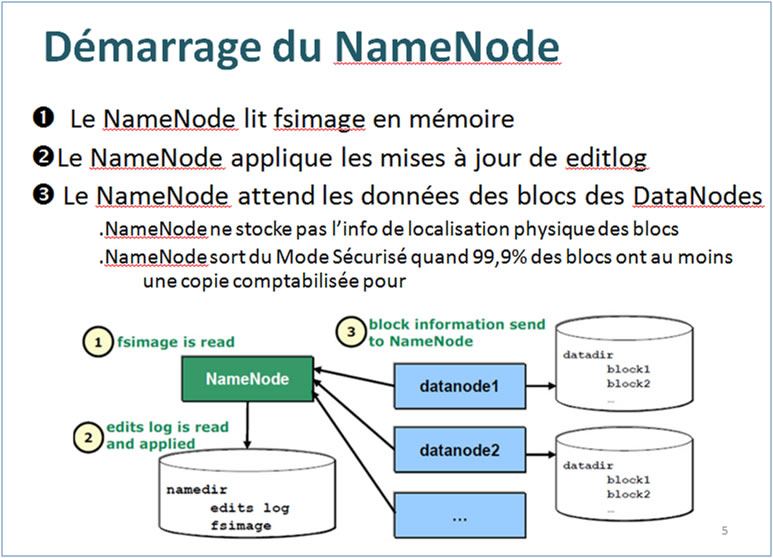
Â
Ajout dâun fichier à HDFS : réplication en mode pipeline
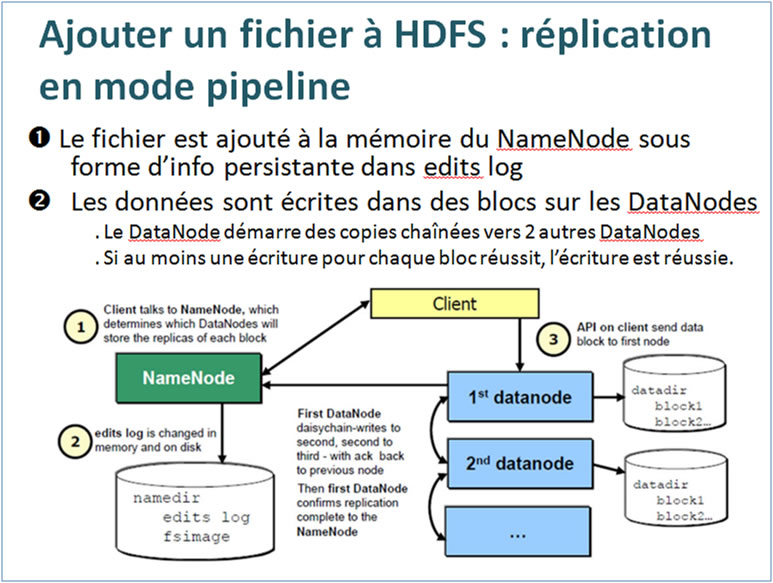
Gérer le cluster :
- Ajout dâun DataNode
- Suppression dâun DataNode
- Contrôle de lâétat de santé du filesystem
|
 |
Yarn (MR2)
Architecture Hadoop : HDFS / YARN / SPARK / MapReduce |
YARN : système dâexploitation de Hadoop permet de gérer des ressources et de planifier des jobs dans Hadoop. YARN vous permet dâutiliser différents moteurs de traitement de données de type batch, interactive, streaming de données stockées dans HDFS. Vous pouvez utiliser Hive pour le SQL, Spark pour les applications in-memory et Storm pour les applications de streaming, toutes sur le même cluster Hadoop.
YARN supporte aussi la conteneurisation sous Docker, ce qui facilite le packaging et la distribution dâapplications.
Evolution de Hadoop v1 Ã Hadoop v2Â :
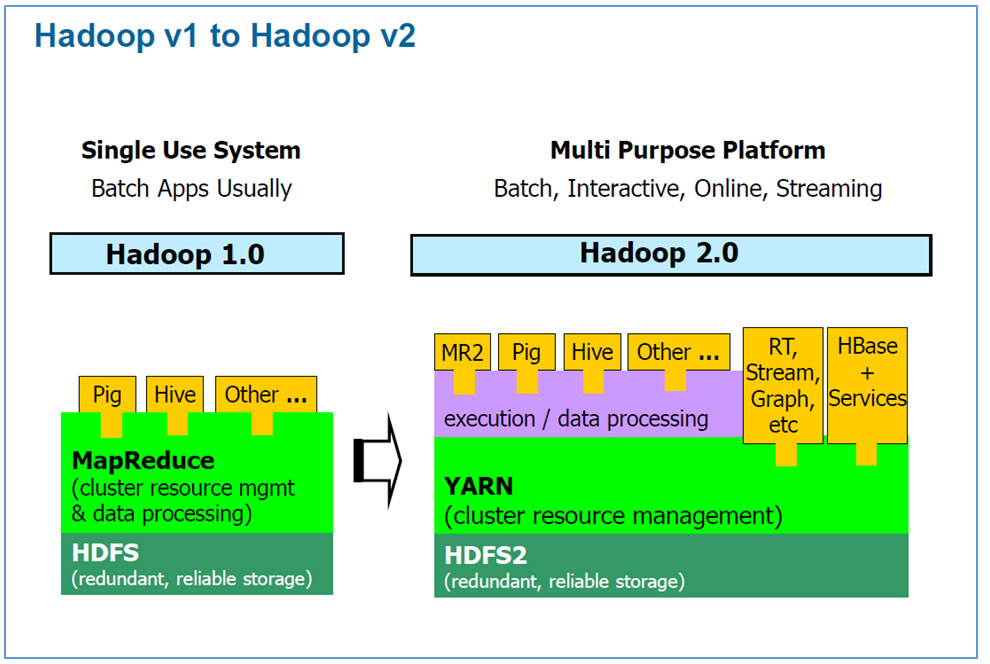
Le principal changement entre Hadoop 1.0 et Hadoop 2.0 est la séparation de la fonction cluster Resource Management & data processing en 2 fonctions distinctes : YARN et MR2
Architecture de YARN :
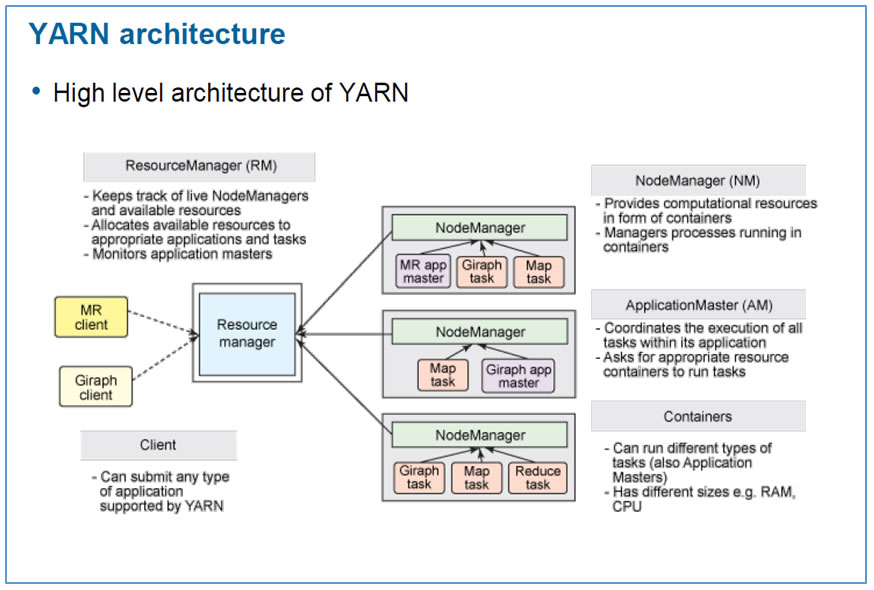
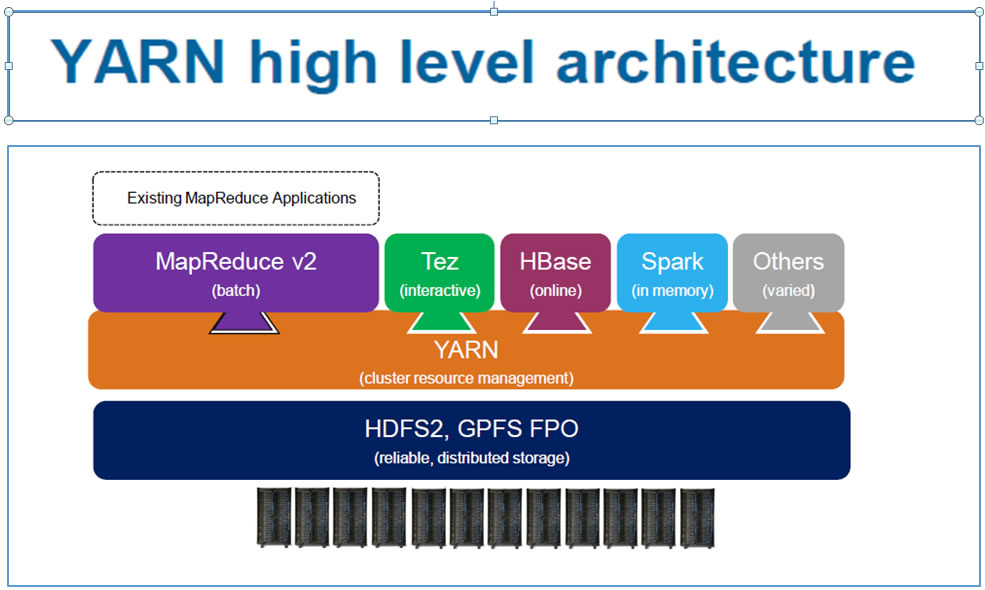
|
 |
Spark 2.4.3
30 Avril 2019 |
Architecture de Spark :
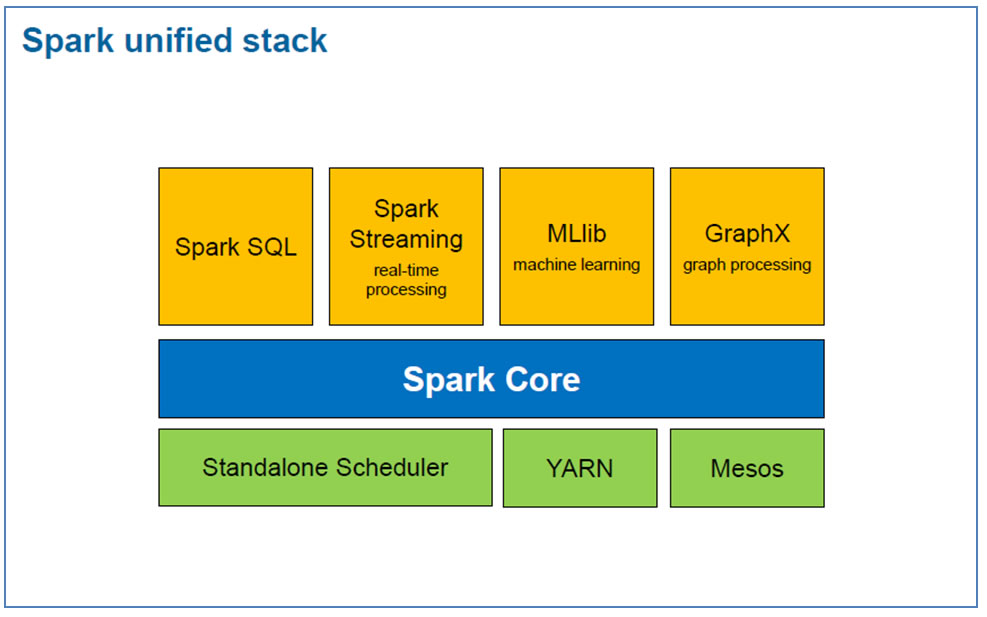
Spark core est au centre de la pile unifiée de Spark ( Spark Unified Stack) Le Spark core est un système général qui permet de planifier, de distribuer et de faire le monitoring des applications à travers un cluster.
- Conçu pour s'étendre à des miliers de noeuds. Il peut tourner sur une variété de gestionnaires de clusters incluant Hadoop YARN et Apache Mesos, ou plus simplement, il peut tourner en standalone avec son propre built-in scheduler.
- Contient des fonctionnalités de base Spark demandées pour faire tourner des jobs et nécessaires pour les autres composants. Le plus important est le concept RDD ( Resilient Distributed Dataset), le principal élément de Spark API. RDD est une abstraction d'une collection distribuée d'éléments avec des opérations et des transformations applicables au fichier. Il est résilient car en cas d'erreurs sur des noeuds il est capable de reconstruire des fichiers.
Grandes fonctions de Spark :
⢠Spark SQL est conçu pour fonctionner avec Spark via SQL et HiveQL (une variante Hive de SQL). Spark SQL pemet aux developers d'appeler SQL via des langages de programmation tels que Python, Scala, and Java.
⢠Spark Streaming permet le traitement de flux de données ( streams ). L'API Spark Streaming se rapporche de l'API Sparks Core's, rendant le travail plus facile pour les développeurs notamment pour déplacer entre les applications ce que les données stockées par les process en mémoire.
⢠MLlib est une library de Machine Learning qui fournit de multiples algorithmes de machine. Exemples : régression logistique, naive Bayes classification, SVM, arbres de décision, random forests, régression linéaire, k-means clustering.
⢠GraphX est une library graphique avec des APIs faites pour manipuler des graphiques et faire du traitement parallèle d données graphiques. GraphX fournit des fonctions pour construire des graphiques et des implémentations des algorithmes les plus importants de la théorie des graphes, tels que ordonnancement des pages seon le rang, composants connectés, chemins d'accès les plus courts possibles.
"Si vous comparez les fonctionnalités des composants de Spark avec les outils de l'ecosystème Hadoop, vous pouvez constater que certains outils sont superflus.
Par exemple,
>>> Apache Storm peut être remplacé par Spark Streaming,
>>> Apache Giraph peut être remplacé par Spark GraphX
>>> Spark MLlib peut être utilisé à la place de Apache Mahout.
>>> Apache Pig, et Apache Sqoop ne sont plus ncessaires davantage,
      et les mêmes fonctionnalités sont couvertes par Spark Core et Spark SQL.
Mais dans le cas où vous avez encore des worflows Pig et où vous avez besoin de faire tourner Pig, le projet Spark vous autorise à lancer du Pig sur Spark.
Â
Les shells et jobs Spark :
Les jobs Spark peuvent être écrits en Scala, Python ou Java ; les API sont dispo pour ces 3 langages.
Les shells Spark sont écrits en Scala ( spark-shell), et en Python ( pyspark )
Le langage natif de Spark est Scalla, alors il est naturel dâécrire les applications Spark en utilisant Scala.
Â
Ce cours présentera des exemples de code Scala, Python, et Java.
Exemples disponibles sur le site GitHuB:
⢠Scala:
https://github.com/apache/spark/tree/master/examples/src/main/scala/org/apache/spark/examples
⢠Python:
https://github.com/apache/spark/tree/master/examples/src/main/python
⢠Java:
https://github.com/apache/spark/tree/master/examples/src/main/java/org/apache/spark/examples
⢠Spark Streaming:
https://github.com/apache/spark/tree/master/examples/src/main/scala/org/apache/spark/examples/streaming
⢠Java Streaming:
https://github.com/apache/spark/tree/master/examples/src/main/java/org/apache/spark/examples/streaming
Les cours Spark Fundamentals sont disponibles sur :
  http://bigdatauniversity.com/bdu-wp/bducourse/spark-fundamentals |
Typologies de Données
Données au repos :
. Solution: Utiliser des commandes standards HDFS : hadoop fs -copyFromLocal ou -put
Données en mouvement :
. Logs générés par plusieurs serveurs constamment modifiés
. Données stockées à plusieurs endroits devant être fusionnées.
. Solution : utiliser Flume ou Kafka
Données depuis une BDD RDBMS ou un Datawarehouse:
. Utiliser Sqoop avec des commandes d'export standard sous forme de fichiers délimités CSV, puis utiliser des commandes Hadoop.
Â
Données depuis un serveur web ou un serveur Log ( en temps réel ) :
. Utiliser Flume ou JMX
. Apache Kafka
. Splunk
. Spark Streaming
 |
 |
Sqoop |
Grandes fonctions de Sqoop :
⢠Transfert de données entre Hadoop et des bases de données relationnelles : utilise JDBC, il faut recopier les drivers JDBC de la BDD relationnelle dans le répertoire $SQOOP_HOME/lib
⢠Utilise MapReduce pour importer et exporter les données.
En Mode Commande :

Consulter Apache Sqoop Cookbook sur Amazon
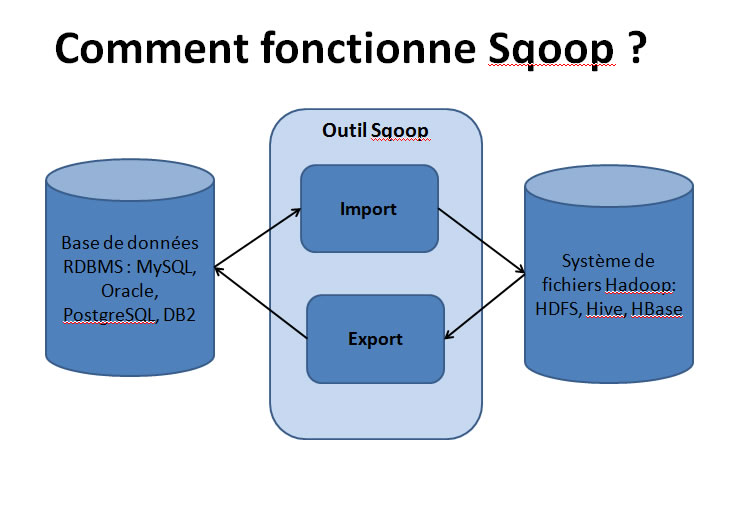
⢠Sqoop import : pour importer des tables individuelles de RDBMS dans HDFS. Chaque ligne d'une table est convertie en 1 record d'un fichier dans HDFS.
Tous les records sont stockés dans des fichiers texte dans des fichiers séquentiels ou Avro.
⢠Sqoop export : pour exporter un ensemble de fichiers de HDFS dans une base de données RDBMS. Les fichiers lus par Sqoop contiennent des enregistrements
qui sont appelés lignes des tables.
Sqoop fonctionne uniquement sous Linux.
 |
 |
Flume
Latin: Flumen, flumenis : rivière |
Comment fonctionne Flume ?
⢠Conçu sur le principe des flux continus entre la source et la cible.
⢠Les flux peuvent être initalisés par des batchs ou autres process
⢠C'est un service distribué, connectable pour collecter, agréger et déplacer des volumes de données importants.
⢠SQOOP a une Architecture simple et adaptable basée sur les fluxx de données en streaming. C'est un outil robuste, à tolérance de pannes et doté de mécanismes de failover et de reprise sur panne.
Les flux sont constitués de noeuds reliés les uns aux autres
⢠Chaque noeud reçoit les données en tant que source, les stocke sur un canal et les envoie via un process appelé ''sink''
⢠Exemples de sources : Avro source, Exec source, Spooling Directory source, Syslog Source, HTTP source, JSONHandler Source...
⢠Exemple d'Interceptors : Flume donne la possibilité de modifier ou supprimer des évènements à la volée. Il est possible de rajouter dans l'entête de l'évènements des infos de Timestamp, le nom de l'hôte ou l'adresse IP, des valeurs statiques, un filtrage par masque pour le corps de l'évènement, un extracteur de groupes à partir du corps de l'évènement, personalisable.
⢠Exemples de sinks : HDFS sink qui écrit des évènements sur HDFS, Logger sink : écrit des évènements LOG niveau INFO, HBaseSInk : écrit des données dans la BDD HBase, ElasticSearchSink: écrit des donnée dans le BDD ElasticSearch
⢠Exemples de canal / canaux utilisé(s) par FLume: canal mémoire, canal JDBC, canal Fichier, canal personnalisé: interface personalisée
Â
 |
 |
Apache Kafka |
Une plateforme distribuée et temps réel pour le Streaming généralement uytilisée pour 2 types d'applications :
- Flux de données en mode pilpeline qui relient les systèmes
- Applications temps réel alimentées en Streaming qui transforme les flux de données
Â
Caractéristiques :
- Solution Open source
- Haut débit
- Faible latence
- Tolérance aux pannes
- Durabilité
- Architecture évolutive et distribuéeÂ
- Variété des cas d'utilisation
- Connection à divers sources de données grâce à Kafka Connect
- Transformation des données avec Kafka Stream
Comment fonctionne Kafka ?
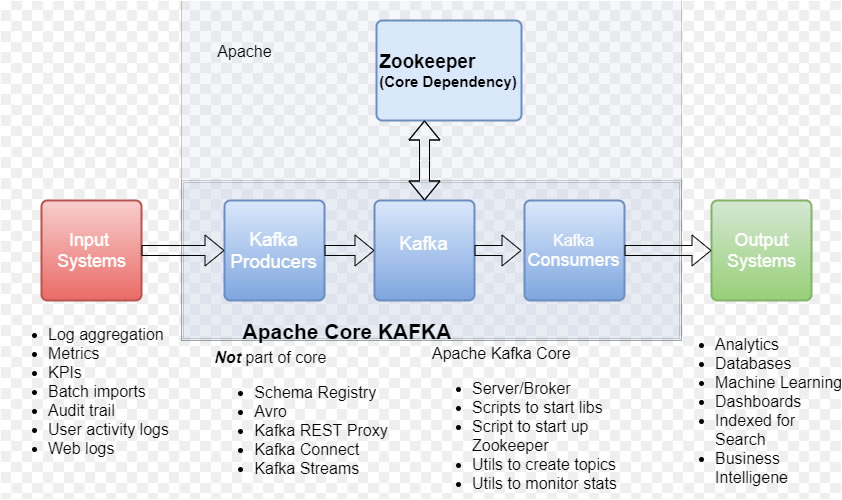
Producers API : permet à une application source de publier un flux de données vers 1 ou plusieurs Topics.
Consumer API : autorise une application à souscrire un abonnement à 1 ou plusieurs Topics.
Streams API : autorise une application à agir en tant que processeur de flux, qui va consommer un flux d'entrée depuis 1 ou plusieurs Topics
et à produire un flux de sortie, après avoir transgformé les flux d'entrée en flux de sortie.
Connector API : autorise à construire et à exécuter des producers et des consumers réutilisables qui se connectent aux topic Kafka.
1 Topic : un flux d'enregistrements.
 |
 |
Apache Oozie |
Workflow Scheduler for Hadoop :
. Scheduler de jobs Apache Hadoop
. Les jobs de flux de données : sont des Graphes Acycliques ( DAGs : Direct Acyclic Graphs )
. Les jobs de coordination de Oozie : sont des jobs récurents à des dates données et selon la disponibilité des données.
. Oozie est intégré avec le reste de la pile Hadoop et supporte différent types de jobs Hadoop tels que MapReduce Java, MapReduce Streaming, Pig, Hive, Sqoop et Distcp, aussi bien que des jobs spécifiques tels que Java et des scripts Shell.
. Oozie est scalable, reliable et extensible.
 |
 |
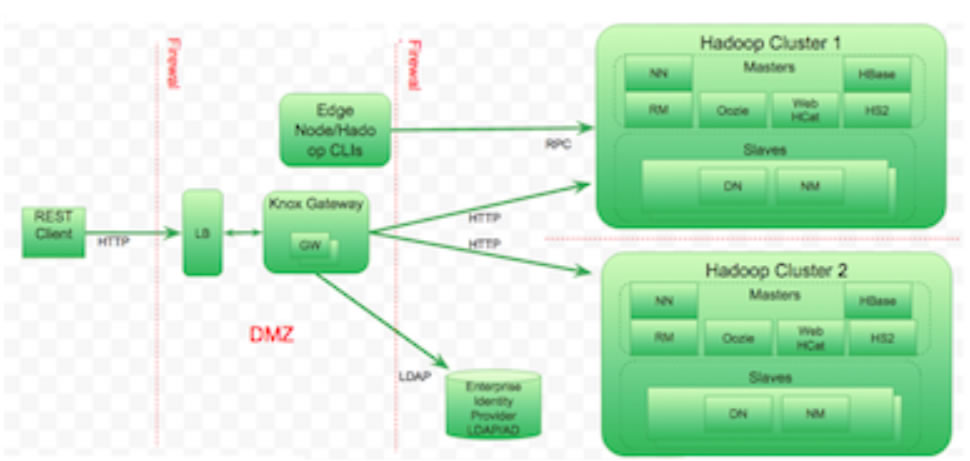
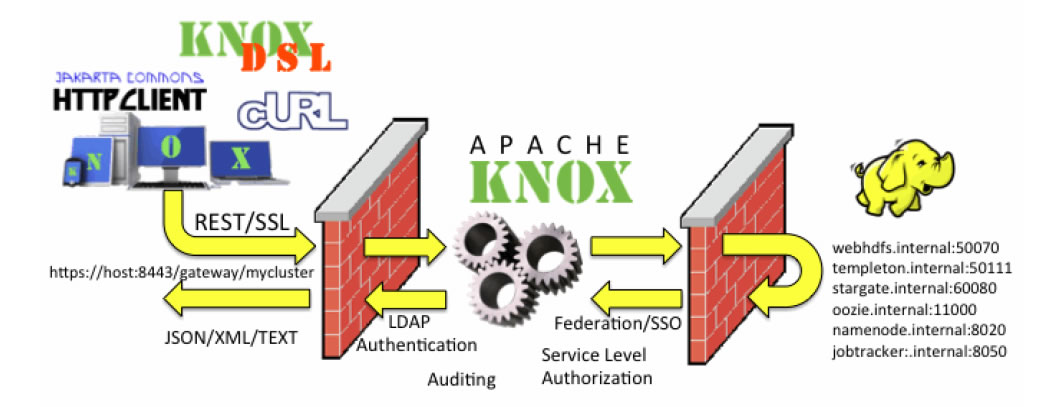
Apache Knox |
Logiciel Gateway Reverse proxy pour interagir avec les clusters Hadoop :
Fonctions principales :
. Interaction avec les interfaces utilisateur : Apache Ambari, Apache Ranger
. Authentification avec les annuaires d'entreprise : LDAP, AD...
. Federation SSO ( Fédération d'identités basés sur Header HTTP )
. Gestion des Droits d'accès
. Audit
Â
La passerellet Knox est un framework joue un rôle :
. de Reverse Proxy
. Sécurité élevée car appel depuis ce serveur de Web Services REST API et HTTP permettant d'ineragir avec les clusters Hadoop.
. Accès supportés : HTTP(S), cURL, Knox Shell (DSL), SSL...
. Accès simplifié grâce aux services encapsulés avec Kerberos et l'utilisation d'un certificat SSL unique.
Â
|
Â
Copyright © by MANAGEMENT INFORMATIQUE All Right Reserved. Publié le: 2019-05-26 (1700 lectures) [ Retour ] |
|
|
